

아스키 코드(ASCII Code)란?
아스키 코드는 문자(영문자, 숫자, 기호 등)를 숫자로 표현하기 위한 가장 초기의 문자 인코딩 규칙이다.
정식 이름으로는 American Standard Code for Information Interchange이다.
이런 규칙이 왜 필요했을까?
컴퓨터는 문자 자체를 이해하지 못한다. 오로지 숫자만 처리 가능한 것이 바로 컴퓨터이다.
그래서 과거 사람들은 이와 같이 약속하기로 했다.
"이 문자를 이 숫자로 표현하자."
변환 흐름
문자 → 정수 → 2진수로 변환하여 저장 및 처리
'A' → '65' → 01000001
아스키 코드의 범위
아스키 코드는 7비트를 사용한다.
표현 가능한 개수 : 27 = 128개 ( 0 ~ 127 )
표현 가능한 개수 : 27 = 128개 ( 0 ~ 127 )
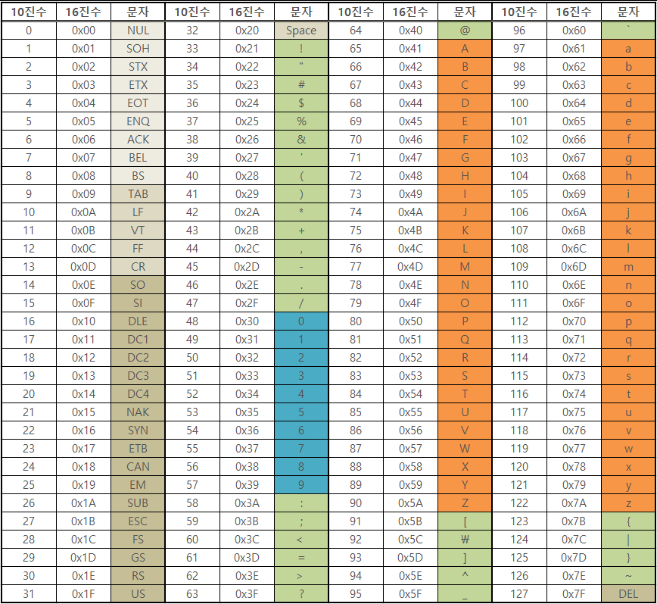
아스키 코드 표
인코딩(Encoding)과 디코딩(Decoding)의 정의
인코딩(Encoding)
의미를 가진 정보를, 정해진 규칙에 따라 데이터 형태로 변환하는 과정
쉽게 말해서
- 사람이 이해하는 정보를(문자, 소리, 이미지 등)
- 컴퓨터가 저장·전송·처리할 수 있는 형태(2진수)로 변환
하는 과정으로 이해하면 이해하기 쉬울 것이다.
인코딩 예시
'A' → '65' → 01000001
디코딩(Decoding)
데이터를, 그 규칙에 따라 원래의 의미로 해석하는 과정
쉽게 말해서
- 컴퓨터가 저장·전송·처리할 수 있는 데이터 형태(2진수)를
- 문자, 소리, 이미지 등 사람이 이해할 수 있는 데이터로 변환
하는 과정을 의미한다.
디코딩 예시
01000001 → '65' → 'A'
"같은 데이터, 다른 해석"의 문제
같은 비트열
01000001- 아스키로 디코딩 → 'A'
- 다른 문자표로 디코딩 → 전혀 다른 문자
이를 통해 데이터는 같아도, 디코딩 규칙에 의해 전혀 다른 의미의 문자로 변경되는 문제가 발생할 수 있다.
그래서 다음과 같은 말이 성립된다.
데이터 자체는 의미를 가지지 않는다.
의미는 해석에서 생긴다.
문자열이 깨지는 이유
동일한 데이터라도 디코딩 규칙이 다르다면 전혀 다른 의미로 해석되어 문제가 발생한다.
문제 상황
- 인코딩 : UTF-8로 진행
- 디코딩 : EUC-KR로 진행
결과 :
안녕하세요 → �����
이유 :
- UTF-8은 1~4바이트로 이루어진 문자의 규칙이다.
- 반면, EUC-KR은 2바이트를 중심으로 이루어진 문자의 규칙이다.
- 바이트 묶는 방식 자체가 다르므로 해당 디코딩 규칙은 같은 데이터를 전혀 다른 의미로 해석하게 된다.
'컴퓨터과학(CS) > CS개념 정리' 카테고리의 다른 글
| 컴파일 언어와 인터프리터 언어란? (0) | 2026.01.31 |
|---|---|
| 빌드(Build) 과정 순서 (0) | 2026.01.27 |
| CS 공부의 시작 (0) | 2026.01.26 |